
Speed Meets Security: How Bottlerocket Optimizes EKS Workloads
Authors: Matthew Hopkins (moebaca)
Determining the optimal host operating system for your EKS worker nodes is critical for establishing a secure and scalable environment for your Kubernetes workloads. Although Amazon EKS is compatible with various Linux OS distributions, AWS specifically publishes optimized AMIs for Amazon Linux 2 (AL2), Bottlerocket and recently throwing a fresh option into the mix with Amazon Linux 2023 (AL2023)! Sticking with an optimized AMI provides out of the box integration with AWS services and environments as well as being backed by direct AWS support which pretty much makes them the de facto choice unless otherwise required.
[Windows Server won’t be covered in this post… sorry Windows admins!]
At Autify, we historically have chosen AL2 as our default EKS worker node host OS simply because it was the only EKS Optimized AMI option for Linux workloads. As the project matures we are now increasingly shifting our attention towards Bottlerocket for its clear-cut benefits in operational efficiency and security due to being purpose built for container orchestration. However, with the recent release of the AL2023 EKS Optimized AMI – featuring updated package management, advanced security enhancements, and improved performance optimizations over AL2 – we now have a viable third option to evaluate!
This article serves to detail why Bottlerocket still stands out as the most attractive EKS Optimized AMI for us at Autify – specifically focusing on workload startup optimizations and security posture enhancements.
Security – Bottlerocket vs. AL2023 and AL2
Worker node host OS security is a topic that should absolutely not be slept on.. especially when options like Bottlerocket exist containing countless secure defaults significantly reducing the development legwork!
Below we’ll examine some key security features across the two Amazon Linux versions and compare them to Bottlerocket’s default configuration.
Let’s dive in!
- Minimal Attack Surface:
- AL2 includes shells, interpreters, and package managers increasing the potential attack surface.
- AL2023 improves on AL2 by updating and removing unnecessary packages but still maintains more components than necessary for a container-focused host OS.
- Bottlerocket reduces the attack surface by eliminating interpreters and shells altogether while also having a very minimal set of dependencies.

Error when attempting to run a shell on Bottlerocket via Lens
- Read-Only Root File System:
- AL2 and AL2023 have a writable root file system potentially increasing the risk of unauthorized modifications.
- Bottlerocket enforces a read-only root file system with dm-verity (more on changing runtime configurations later).
- SELinux Configuration:
- AL2 provides optional SELinux support which may not be as stringent without manual configuration.
- AL2023 enables SELinux by default but in a permissive mode which logs but does not enforce policy violations.
- Bottlerocket applies SELinux in enforcing mode by default offering isolation and mandatory access controls that restrict potential escalations.
- System Updates:
- AL2 employs package-based updates using Yum which can lead to dependency conflicts and require manual intervention for resolution.
- AL2023 streamlines system updates with deterministic upgrades and now uses DNF over Yum enhancing predictability and stability in update processes.
- Bottlerocket adopts a completely different approach with image-based updates via TUF relying on an atomic update mechanism that reduces update complexity and increases reliability.

- System Configuration:
- AL2 and AL2023 system configuration files are directly accessible and modifiable unless otherwise managed.
- Bottlerocket uses an API for configuration changes isolating the settings from direct access and enhancing security through controlled modifications.
- Hardened Application Binaries:
- AL2 and AL2023 do not explicitly document the same extent of binary hardening practices across all system binaries as Bottlerocket does.
- Bottlerocket ensures all executables are built with hardening flags reducing the risk from various common exploit techniques.
- Secure Boot Process:
- AL2 does not inherently support UEFI Secure Boot.
- AL2023 introduces UEFI Secure Boot providing support for a more trusted boot process.
- Bottlerocket enables Secure Boot for all new variants on platforms that support UEFI boot.


To summarize – while AL2023 definitely brings solid security enhancements over AL2 (great work EC2 service team!), Bottlerocket still eeks out a clear win for security-conscious environments (at the cost of some flexibility like a mutable filesystem of course). Its architectural integrity, strict access controls, and immutable update mechanism provides for a security posture custom tailored for containerized workloads (assuming your requirements allow for the flexibility tradeoffs).
For more info on AL2023 – AWS has published a doc on how AL2 compares to it here.
Workload Startup Optimization – Bottlerocket vs. AL2023 and AL2
The speed at which new worker nodes become available for unschedulable pods is critical for maintaining service availability in highly dynamic Kubernetes environments. At Autify we have several workloads that are scaling up and down by dozens of pods at any given moment which can require a number of worker nodes to spin up via cluster-autoscaler.
When looking to improve our scaling performance we were focused on the following:
- Worker Node Startup Time: Time from when a pod scheduling event fails to when a new node is ready for the pod to schedule on.
- Container Image Caching: A native container image caching architecture which dramatically speeds up pod startup time on fresh nodes.

As displayed above – Bottlerocket’s OS architecture specifically shines in both metrics offering an immutable operating system with fewer moving parts and built-in image caching with a dedicated data volume. In contrast, AL2 and AL2023 require quite a bit of tinkering to achieve similar image caching gains on a fresh node which translates to more operational overhead.
Worker Node Startup Time Benchmarks
In order to benchmark worker node startup time we will look at the Events of pods as they transition from cluster-autoscaler performing a TriggeredScaleUp event to the time when the pod reaches the Scheduled state.
We will create 3 EKS managed node groups – AL2, AL2023 and Bottlerocket – that will each use the r6a.large Amazon EC2 instance type in a single availability zone in us-west-1. We will then launch 3 pods per node group. Each pod will have large enough requests set to scale up a unique EC2 instance for each ultimately creating 3 worker nodes per node group. After the scaling activities are complete we will then capture the event timestamps via kubectl describe pod and compare the average node bootstrap times per AMI.
🗣 Note:
The benchmarks below offer only a preliminary insight into startup performance. For a comprehensive evaluation, we recommend conducting additional tests using the specific instance types and availability zones tailored to your actual workloads – conducting many simultaneous runs in order to cut down on potential variability/anomalies .
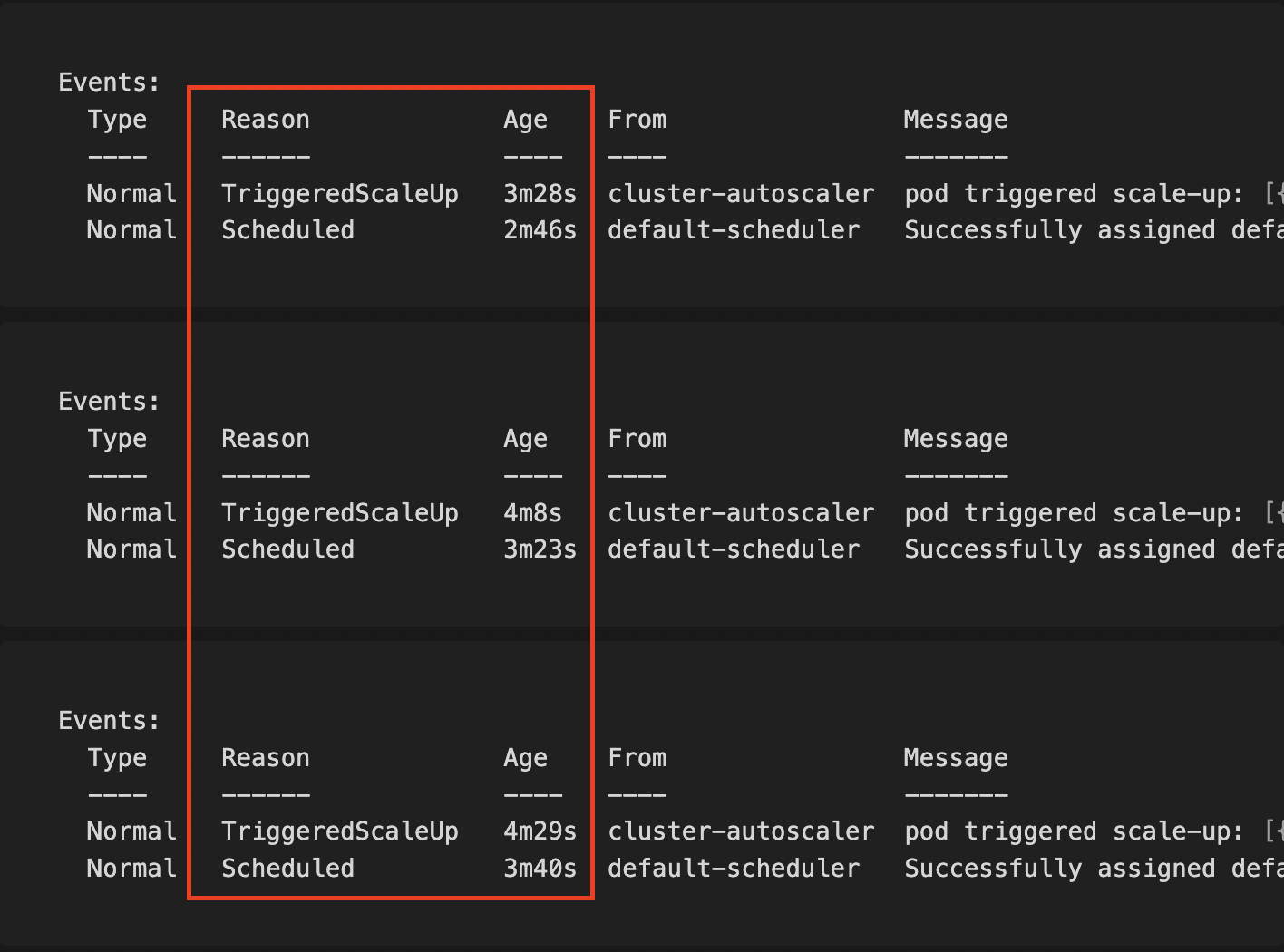
Amazon Linux 2
Times: (3m28s – 2m46s) = 42s; (4m8s – 3m23s) = 45s; (4m29s – 3m40s) = 49s
Average: (42s + 45s + 49s) / 3 = 45.33 seconds
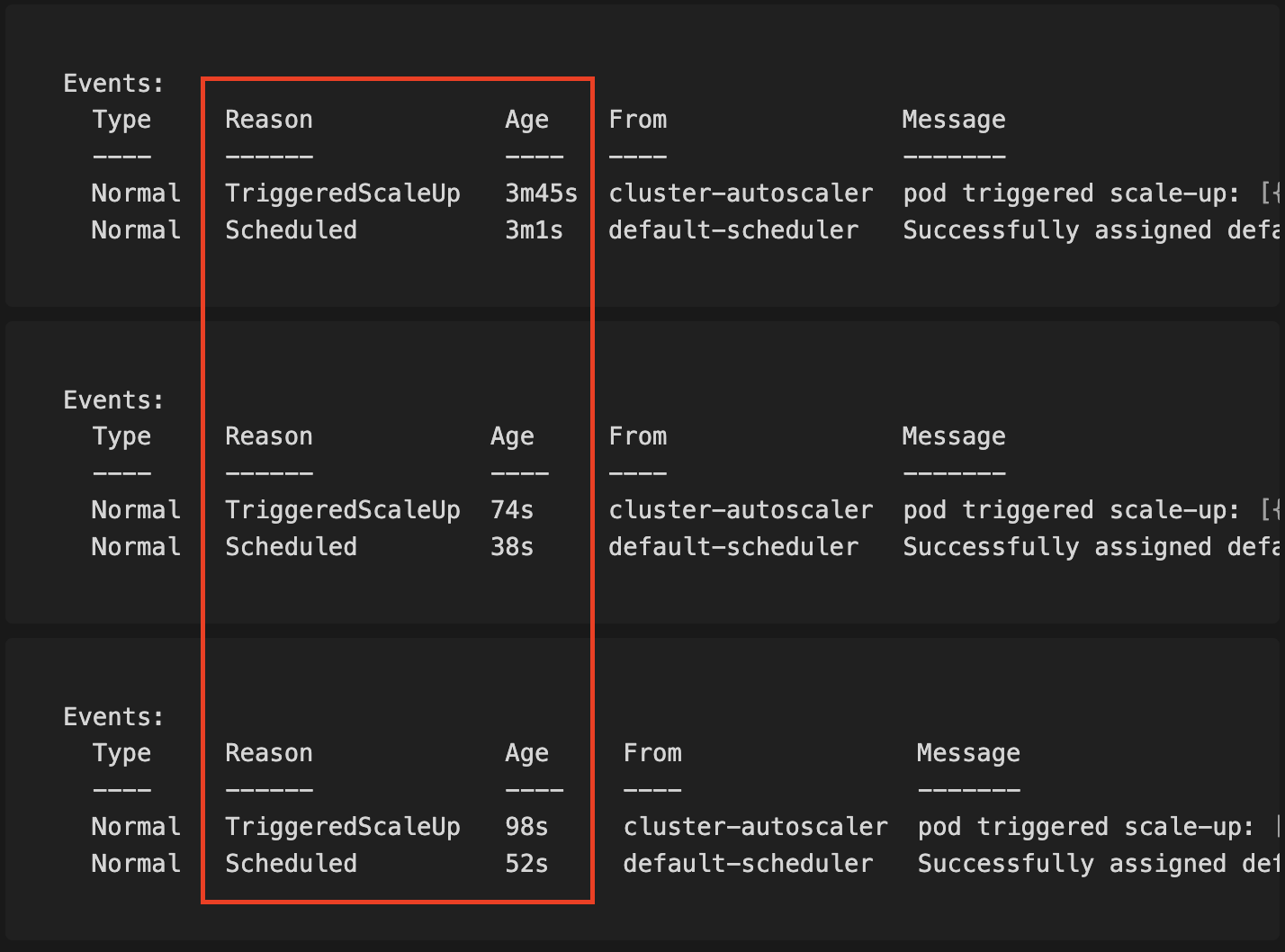
Amazon Linux 2023
Times: (3m45s – 3m1s) = 44s; (74s – 38s) = 36s; (98s – 52s) = 46s
Average: (36s + 44s + 46s) / 3 = 42 seconds
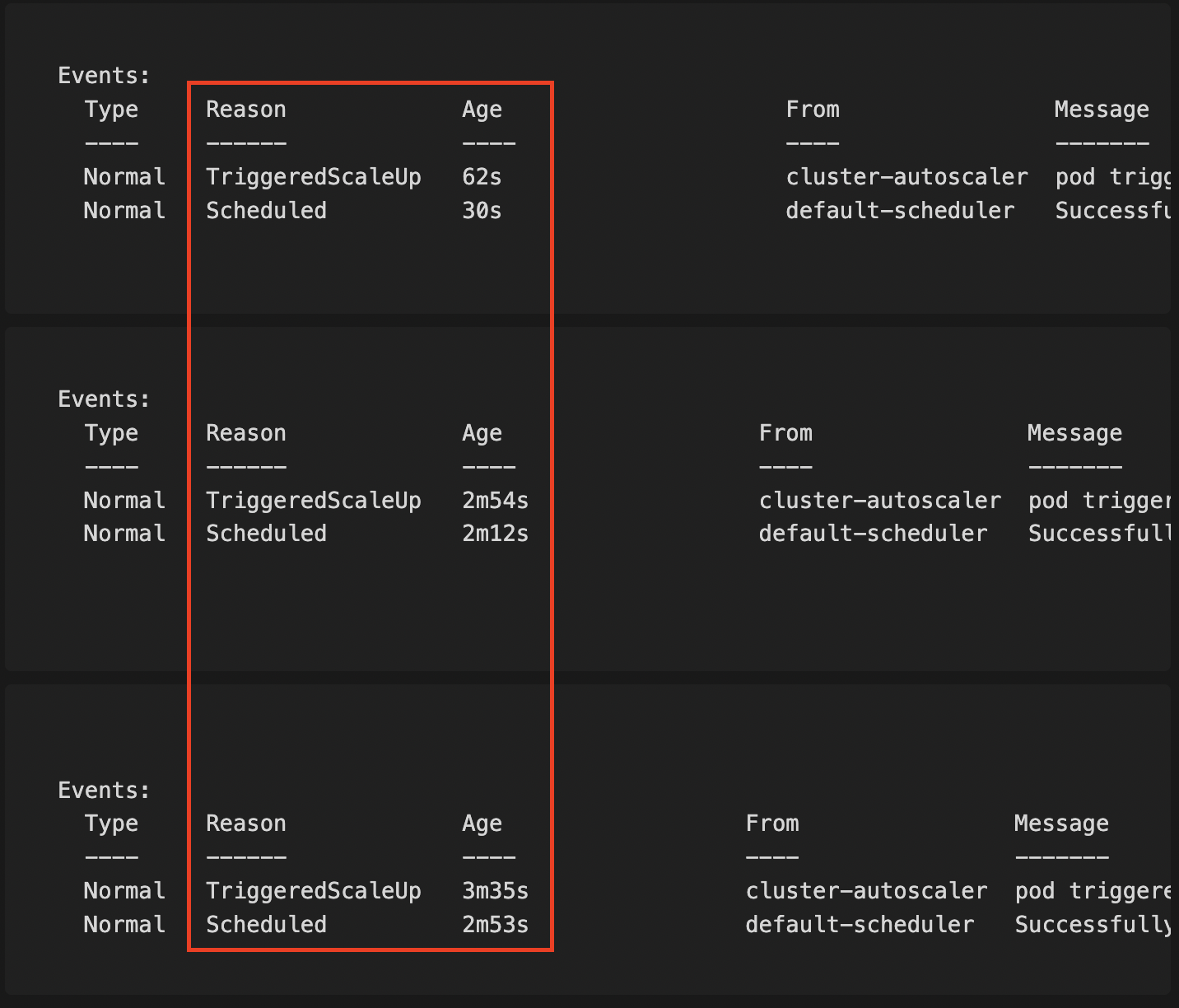
Bottlerocket
Times: (62s – 30s) = 32s; (2m54s – 2m12s) = 42s; (3m35s – 2m53s) = 42s
Average: (32s + 42s + 42s) / 3 = 38.67 seconds
Node Startup Time Summary
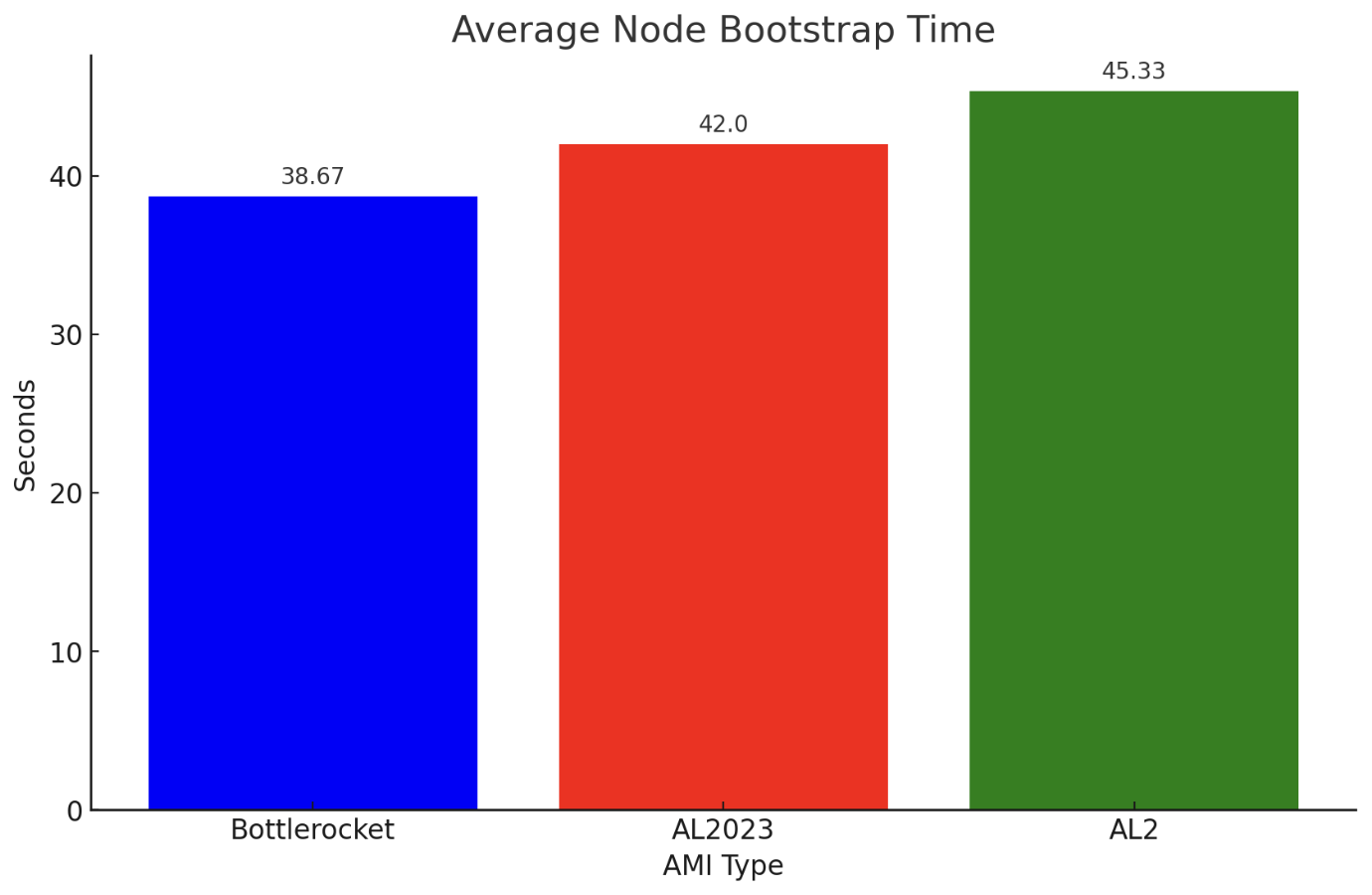
With the results above in hand we can see that Bottlerocket leads with the quickest average startup time of 38.67 seconds. AL2023 follows closely with an average time of 42 seconds, showing a slight improvement of performance over AL2 which averaged at 45.33 seconds. While extremely preliminary, these results suggest Bottlerocket does indeed have an edge in startup efficiency, with AL2023 as a promising upgrade from AL2.
Container Image Caching
Bottlerocket is designed with a native container image caching architecture that extremely simplifies implementing caching for new worker nodes. While AL2 and AL2023 can also benefit from image caching after some customization, this requires quite a bit more leg work.
🗣 Attention!
Please take note of your workload’s imagePullPolicy and understand that if you use “Always” it could potentially negate the benefits of the data volume image cache. Prefer “IfNotPresent” as a best practice (the default image pull policy if left unspecified).
Bottlerocket Data Volume Caching Implementation
In order to leverage the data volume for image caching performance gains you can either follow the AWS docs or pull down this handy script provided by AWS.
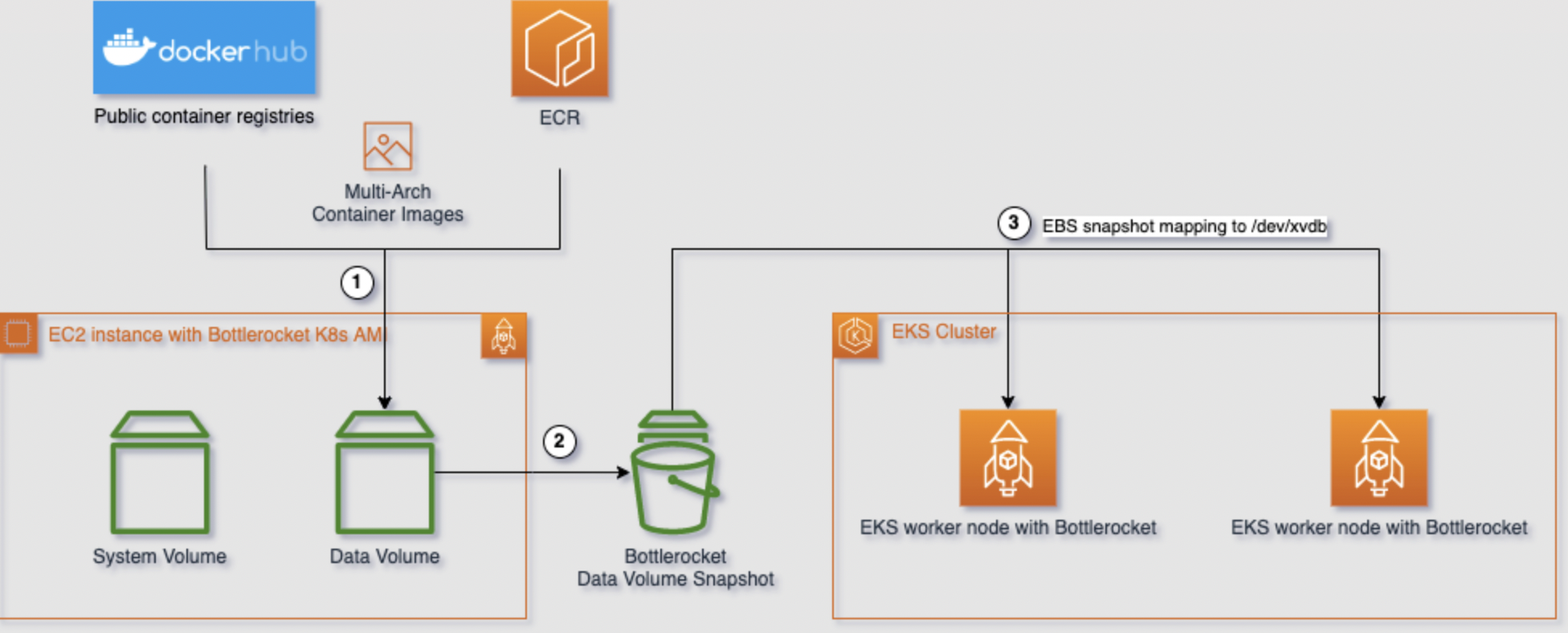
The script is essentially just an automation of the manual steps from the docs and are performed as follows:
- Launch an EC2 instance with the Bottlerocket AMI
- Perform remote access to the instance via Amazon System Manager
- Pulls container images supplied to snapshot.sh as params to be cached using Amazon System Manager Run Command
- Shuts down the instance
- Creates an EBS snapshot
- Terminates the instance
You can then update your launch template for your Bottlerocket node group to use the snapshot for /dev/xvdb (/dev/xvdba being the root volume).
If you use the Terraform EKS module this can all be baked into your CI/CD process when building a new container image and applied like this example:
eks_managed_node_groups = {
bottlerocket = {
name = <nodegroup name>
instance_types = <instance types>
...
block_device_mappings = {
# Root volume
xvda = {
ebs = {
volume_type = "gp3"
volume_size = 5
delete_on_termination = true
}
}
# This will be used for Bottlerockets's data directory - make sure to input the snapshot id (e.g. snap-xxxxxxxxxxxxxxxxx)
xvdb = {
device_name = "/dev/xvdb"
ebs = {
volume_type = "gp3"
volume_size = 20
snapshot_id = <snapshot id>
delete_on_termination = true
}
}
}
}
}New worker nodes that spin up in that node group will now have the latest snapshot automatically mounted to the data volume and container caching should work flawlessly! If you do not see the caching improvements please be sure to check that your imagePullPolicy isn’t specified (default) or is not explicitly set to “Always”.
Example Caching Benchmark
The added value of Bottlerocket isn’t the actual improvement of caching itself, but rather the native support for caching integrated into the OS architecture as explained above. However, for those new to the concept of caching performance, we’ll present a quick example to illustrate the significant impact container image caching can have on pod startup times just to cover all bases in this post. If you’re already familiar with container image caching mechanics, please feel free to jump ahead to the summary.
Typically when following best practices container sizes should be kept as minimal as possible. Sometimes images can get quite bloated in size depending on the software. For our example we will use the CircleCI Android Image which is ~3GB in size and should truly show off the power of container image caching by first performing a pull on a fresh node followed by a cached pull:
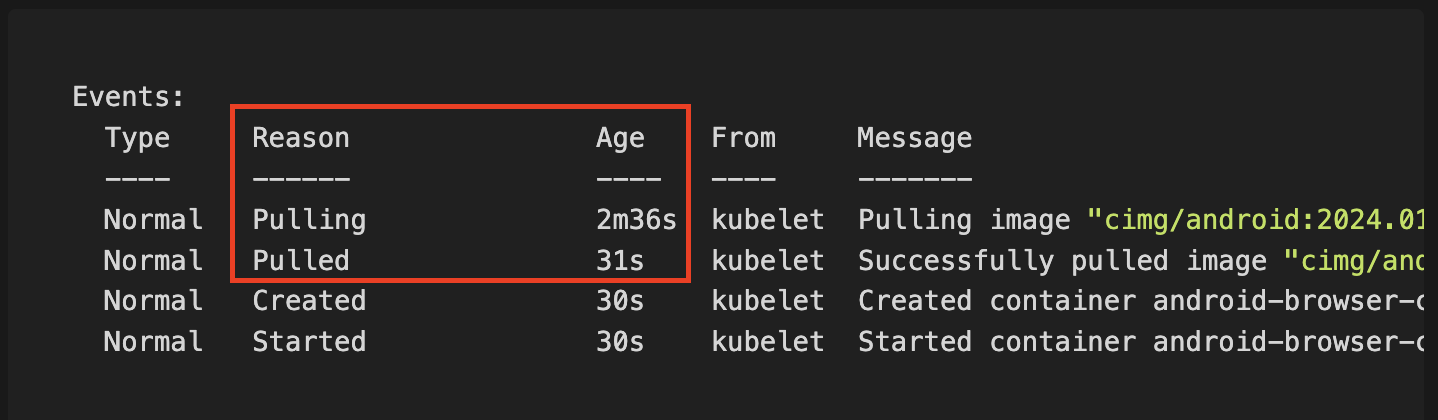
Time: (2m36s – 31s) = 32 seconds
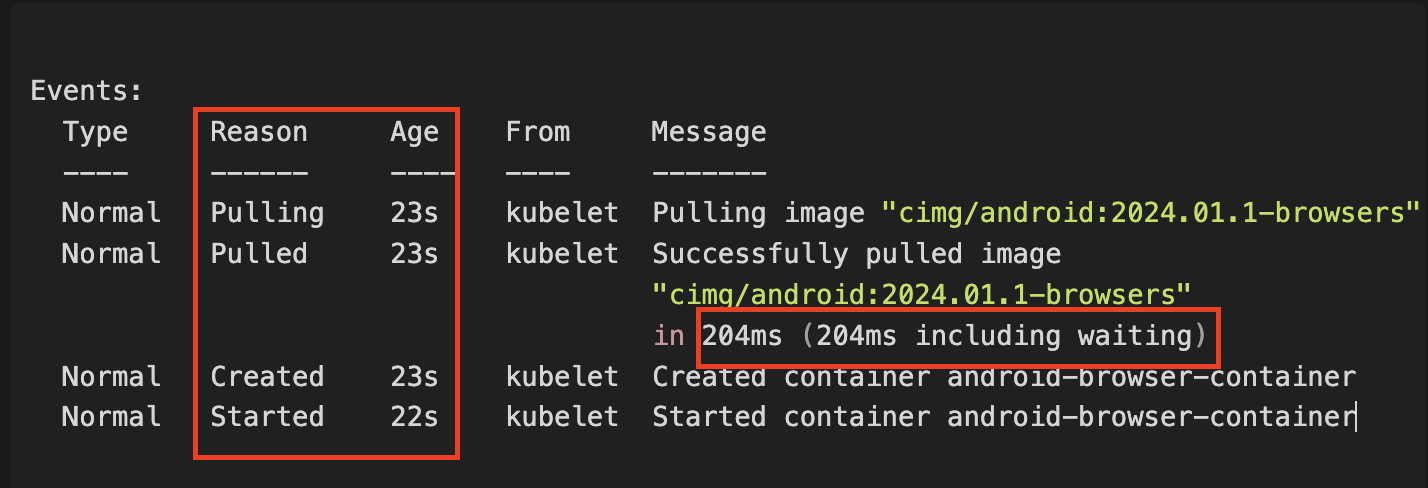
Time: (23 – 23) = 204ms
Caching the container image reduced the time in our example image of ~3GB from ~32 seconds until pod readiness to practically 0 seconds.
Summary
In this post we dove into the various security and scalability advantages provided by Bottlerocket over Amazon Linux 2 (AL2) and the recently released Amazon Linux 2023 (AL2023) as a host operating system for EKS worker nodes.
Bottlerocket consistently demonstrated faster node readiness for which our preliminary benchmarks showed an average of ~6 seconds faster readiness over AL2. In addition, the native container image caching architecture allowed us to easily adopt caching shaving off ~>37 seconds per pod on a fresh node for one of our workloads at Autify! That means new pods that are unschedulable are now spinning up ~>40 seconds faster using Bottlerocket over AL2.
While AL2023 marks a notable improvement over AL2, choosing Bottlerocket for our EKS environments at Autify is now the gold standard!